今回は、splitノードとjoinノードでデータがどのような順番で処理されていくのかを確認します。最後にこの性質を利用したフローを紹介します。
splitノードとjoinノードの基本
最初に、splitノードとjoinノードを使ったことがない方向けに基本の動作を説明します。
Node-RED Cookbookの中では以下の様に説明されています。
Split ノードは配列の各要素を送信するために使用します。 これに個々の要素に対して必要な操作を行うノードが続き、 その後 Join ノードによって、単一の配列に再結合します。
Node-RED Cookbook
配列のそれぞれデータを取りだして、何かしらの処理をしたいケースがあると思います。Cookbookのフローサンプルでは、SplitとJoinノードを使って、それぞれの値を四捨五入する例が示されています。
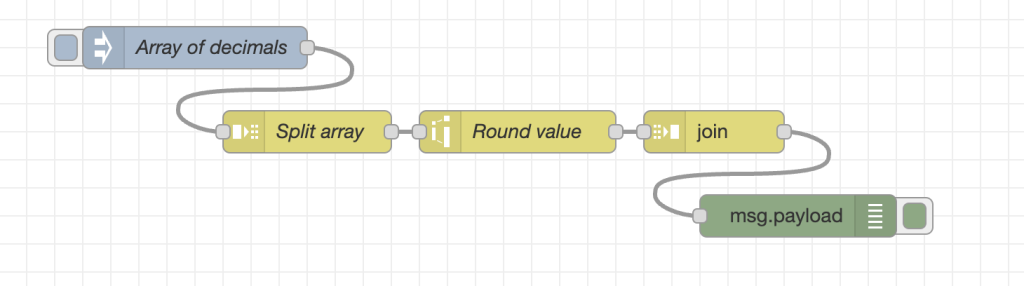
入力データ:[1.67,2.98,3.12,4.99,5.50]
処理:整数に四捨五入
処理結果:[ 2, 3, 3, 5, 6 ]
入力された配列の要素をそれぞれ四捨五入して、再度配列にまとめ直してくれています。splitとjoinはセットで利用するのが良さそうなのがわかります。
分岐するケースでの問題
次にsplitノードで分割した値を条件分岐するフローを考えます。例えば、先ほどの入力データのうち、4以上の数値だけを取り出したい場合のフローを作って実行してみます。条件分岐は、Switchノードを使います。

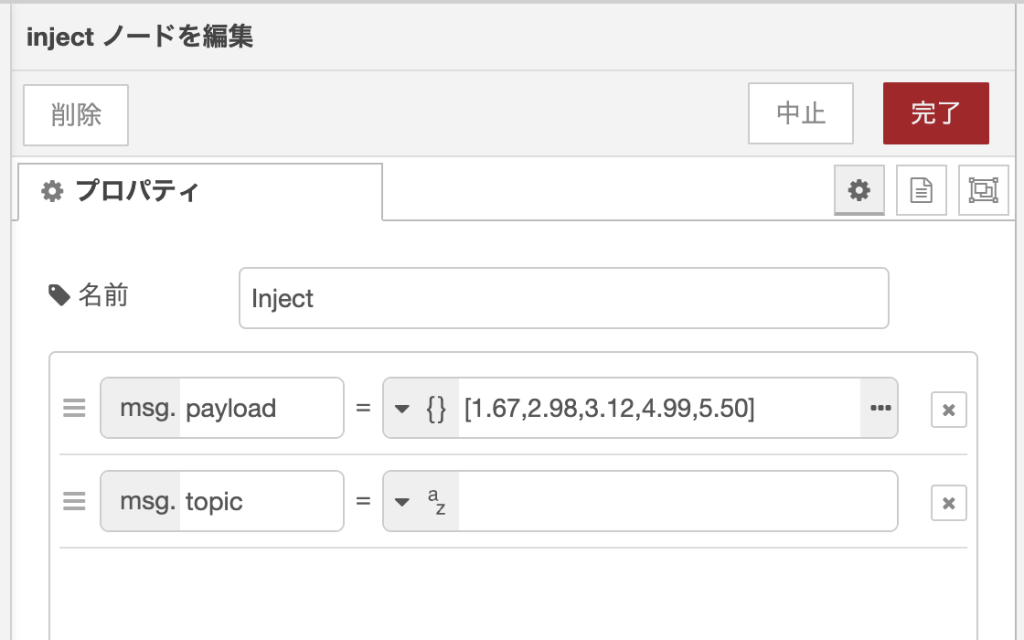
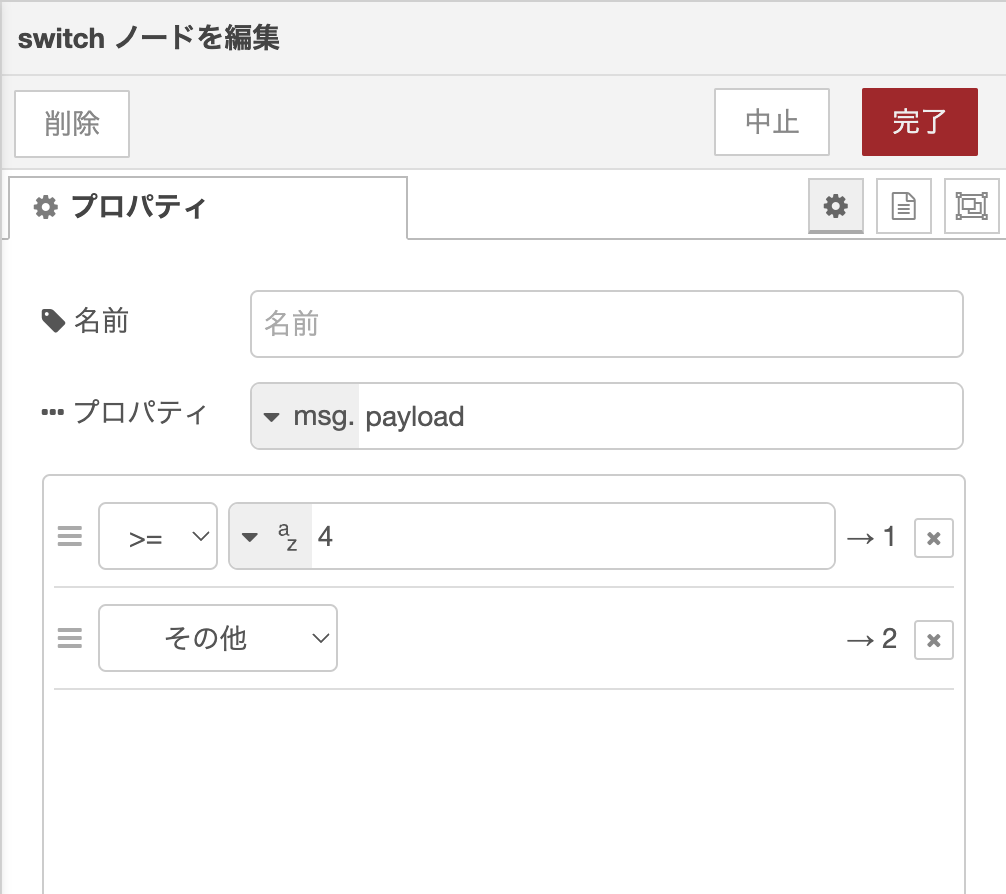
入力データ:[1.67,2.98,3.12,4.99,5.50]
処理:4以上の数値かどうかを判定
処理結果:配列は分割されたので、debugノードにはそれぞれ出力されます。

この処理結果を、ひとつの配列にまとめなおしたい場合はどうすればよいでしょうか。
うまくいかないケース
すぐに思いつく方法としては、Switchノードの後に、joinノードを追加することです。しかし、これでは、実行しても期待した結果は得られません。

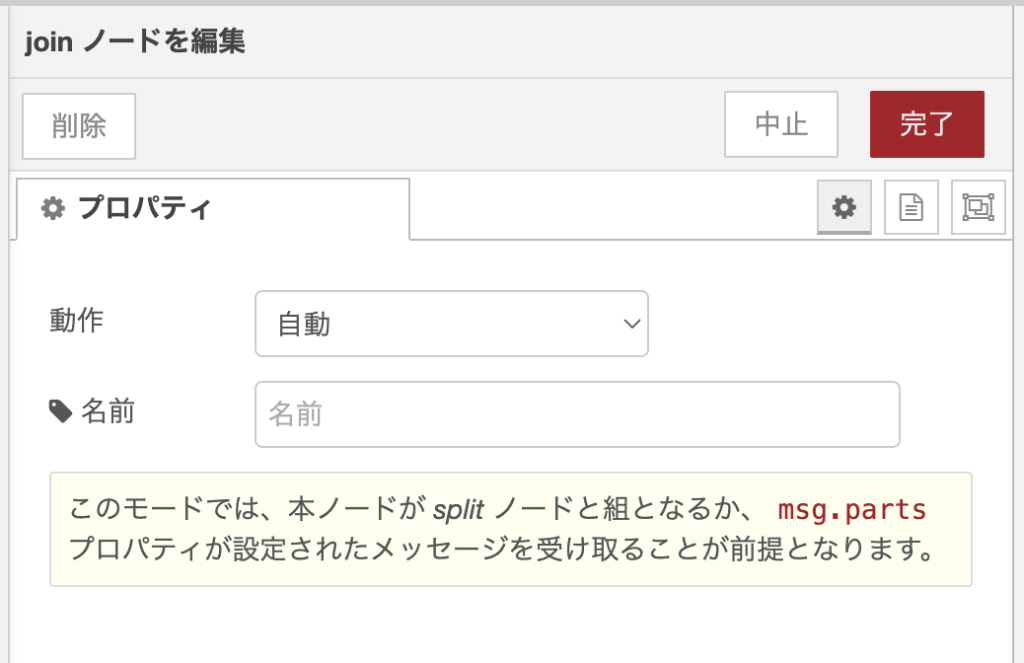
なぜなら、joinノードは値の到着を待ち続けているからです。
1個ずつバラバラなデータが上流から流れてくるので、どこまでデータが来たら一つにまとめるのかを判断する基準が必要です。joinノードは自動的に判定することもできますが、手動で基準を決めることもできます。
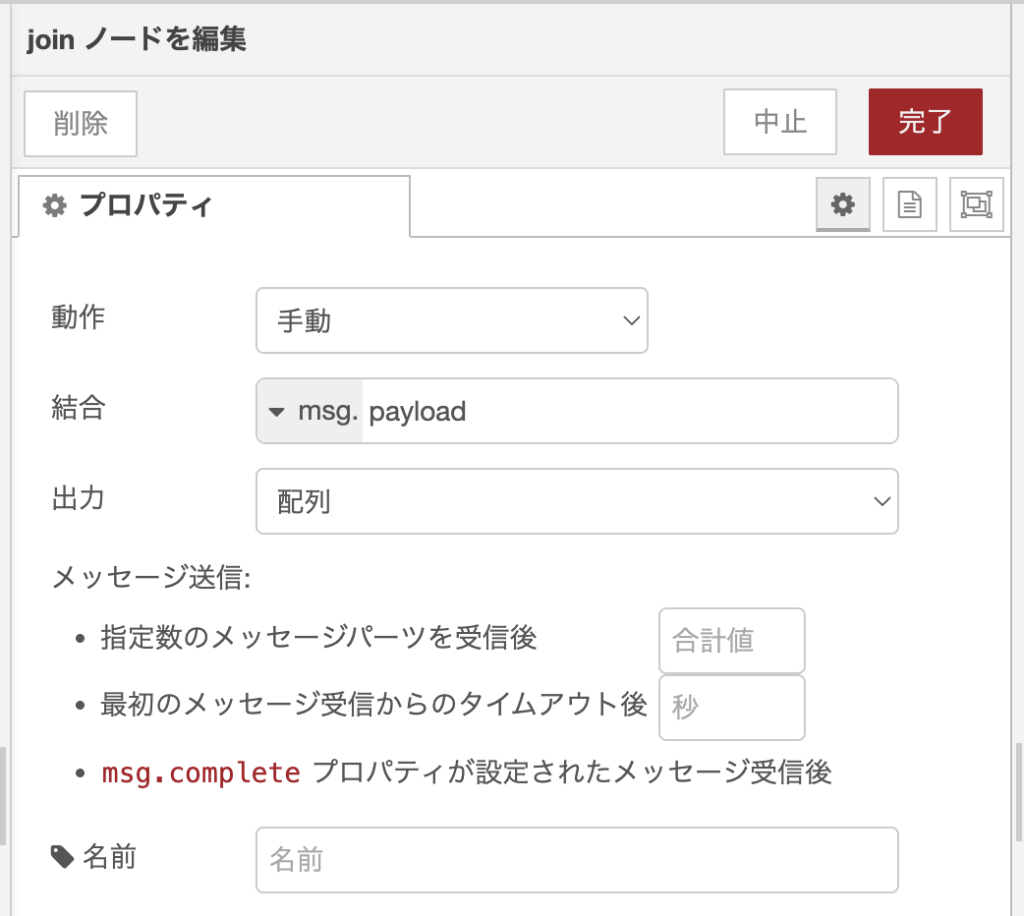
例えば、先ほどの配列の中に4以上のデータは2個あるので、指定数のメッセージパーツを受信後の合計値を2とすれば、フローの結果が得られます。

これでは、入力データ:[1.67,2.98,3.12,4.99,5.50]のうち4以上のデータは2個あるということを、事前にわかっていないと目的のフローを作れないことになりますので少々不便です。
解決するには
swtichノードの次にjoinノードを直接接続するのではなく、下図のようにsplitノードに接続します。
switchノードの先には、changeノードとJSONata式を使って、フローコンテキストに値を保存しておきます。

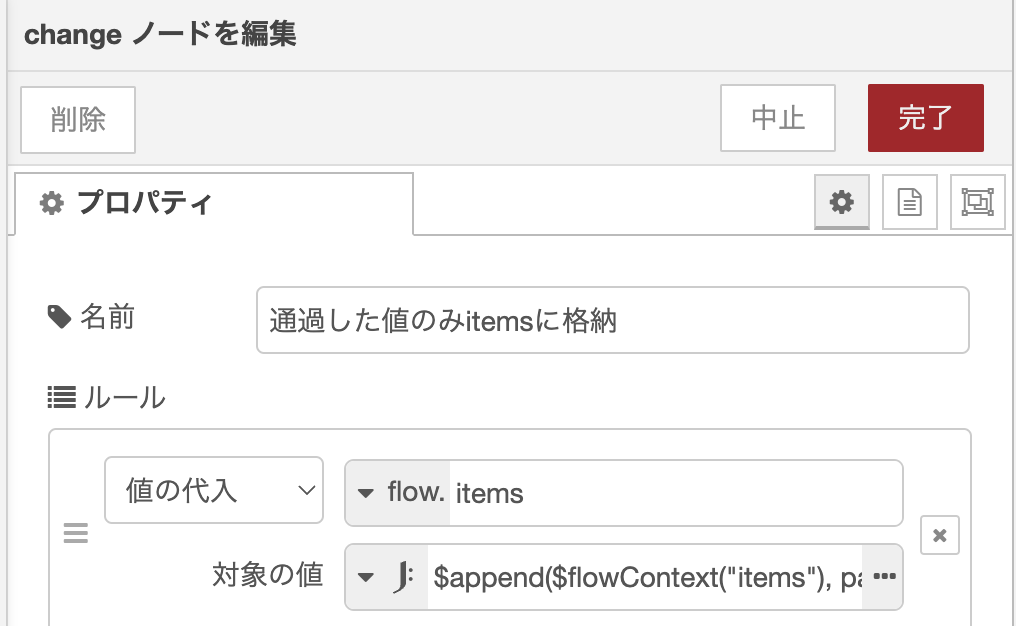
JSONata式 : $append($flowContext(“items”), payload)
Switchノードに繋いだフローが最後まで値を処理するとjoinノードはそのタイミングでスタートして、次のフローを動かします。
フローコンテキストに格納された配列のデータをchangeノードでmsg.payloadに戻せば、期待した処理結果になります。
最後にフローコンテキストのデータを削除する処理も入れています。
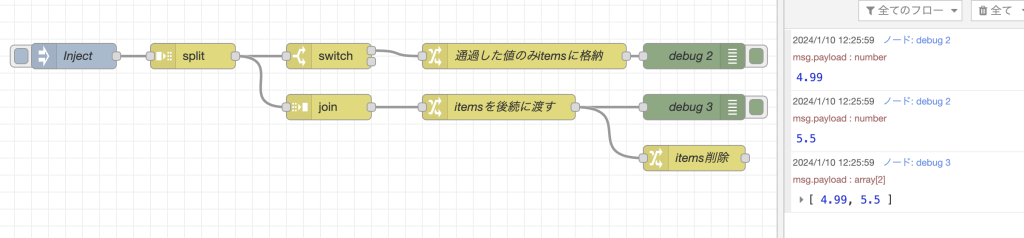
splitノードとjoinノードの動作順序
ここで、splitノードとjoinノードの動作順序を確認しておきましょう。
サンプルフロー
入力データ:[ 1, 2, 3, 4, 5, 6, 7 ]
処理:
- 1から7の数値配列をsplitします。
- Switchノードで、偶数か奇数かを判定します。
- 奇数値のみの数値配列を作成します。
処理結果:[ 1, 3, 5, 7 ]
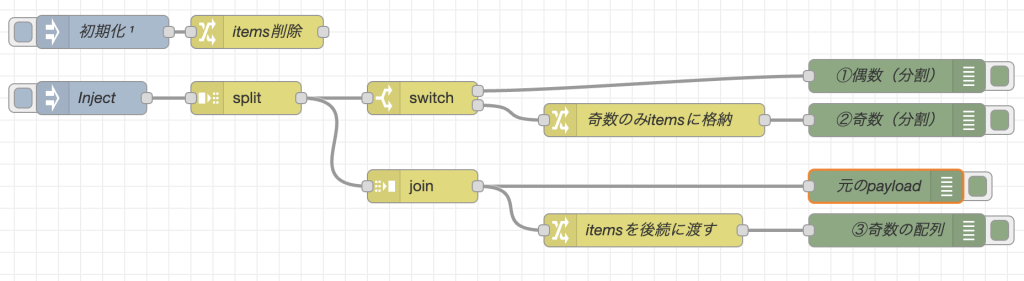
フローの実行結果
- debugノードの出力順を見てください。
- 初めに「偶数(分割)debugノード」に偶数が一つずつ出力されます。
- 次に、joinノードで要素の再統合が行われ、「元のpayload debugノード」に出力されます。
- 次に「奇数(分割)debugノード」に奇数が一つずつ出力されます。
- 最後に、「奇数の配列debugノード」に奇数のみの配列が出力されます。
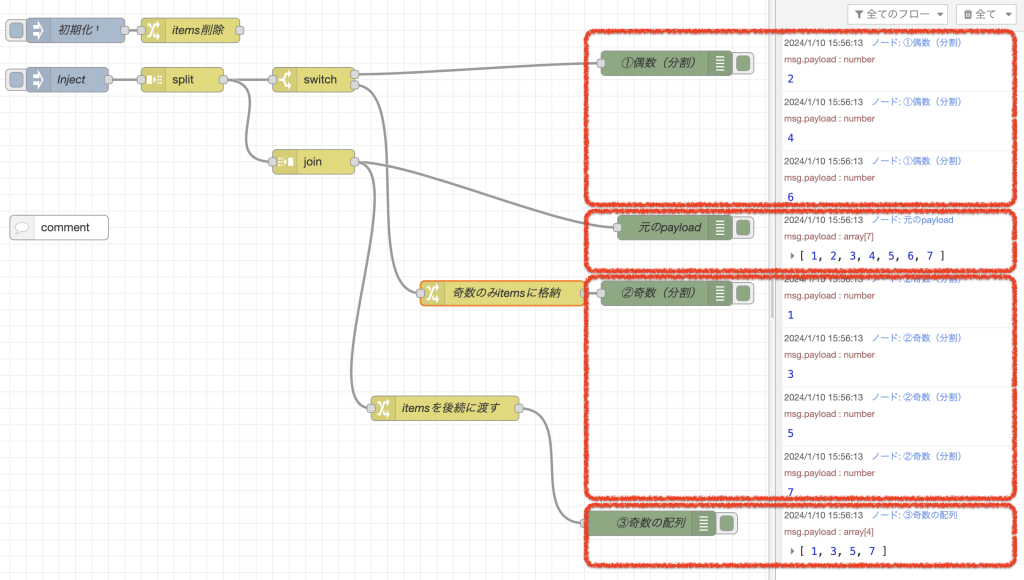
一度、joinノードからデータが流れていますが、その後もう一度joinノードからデータが流れています。
タイミングとしては、swichノードの後にあるchangeノードでフローコンテキストへのデータ格納が終わってから、joinノードのあとのchangeノードにデータが流れています。
結果として、配列に格納し終わったフローコンテキストの内容がデバッグに出力されています。
応用例
先ほど調べた性質を利用すれば、後続のフローで配列の長さがわからなくても、期待した処理ができることがわかります。
以前、初心者向けにWebスクレイピングをやってみるYoutubeで作ったフローがこちらです。
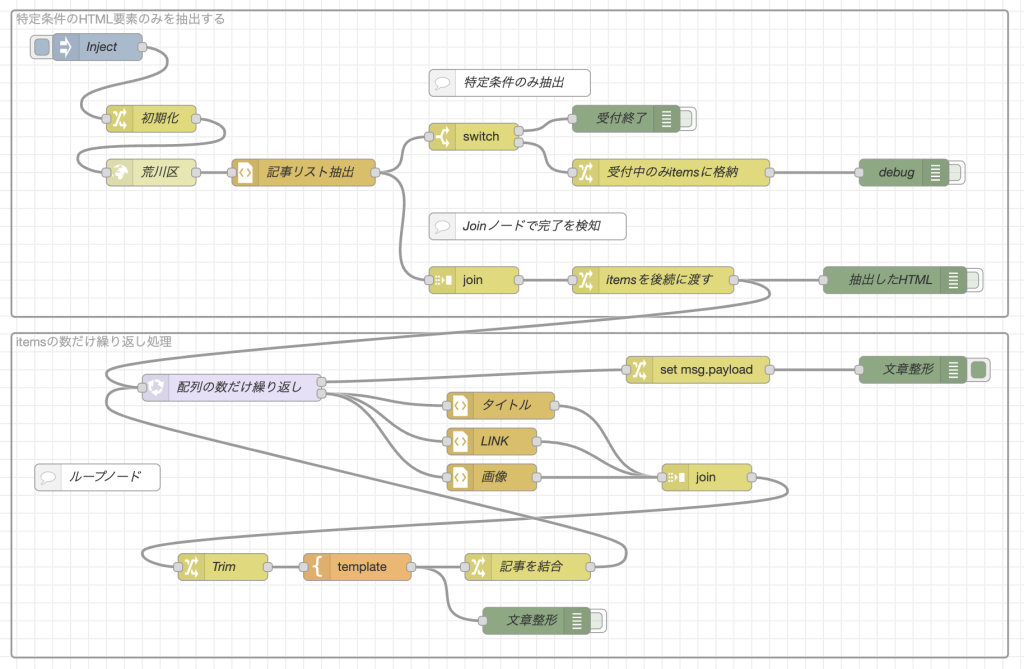
このフローの上段に注目してください。HTMLノードとjoinノードのセットで使っています。
HTTPノードを使ってウェブサイトにアクセスしてそのページの内容をHTMLノードでスクレイピングしています。HTMLノードはsplitノードのようにHTMLの抽出した内容を要素毎にバラバラにして次のフローに渡すことができます。
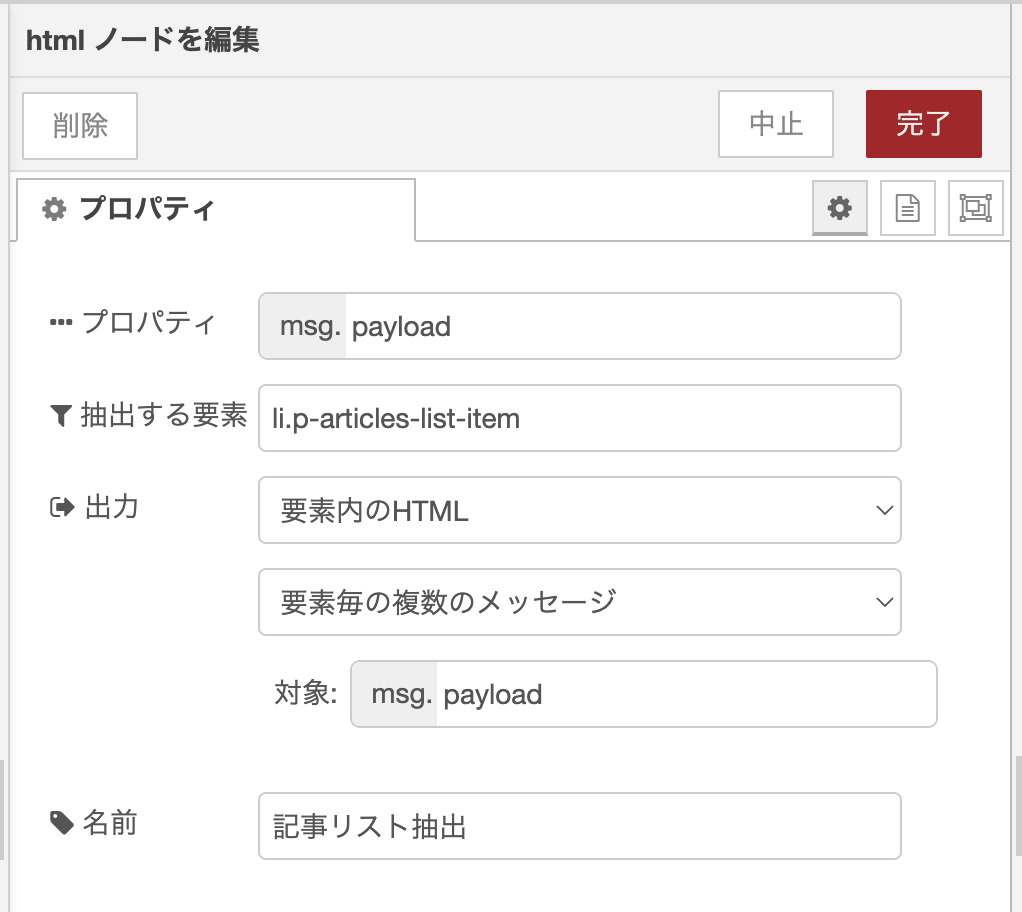
しかし、Webページ内に抽出できる要素が何個あるのか事前にわかりません。そのため、何個の要素が次のフローにやってくるかわかりません。そのため、先ほど調べたjoinノードの性質を利用することによって、HTMLノードで抽出した要素ごとに特定条件に当てはまる記事だけをitemsに格納しています。
全部格納し終えたら、joinノードがスタートして、後続の処理につなげています。
まとめ
今回は、Node-REDの標準ノードであるsplitとjoinを使って、その処理の順番について調べました。
今回使用したフローは、こちらから自分のプロジェクトにインポートできます。
https://enebular.com/discover/flow/54867ea4-3868-4d2a-992d-b01c6c3859f2
ぜひ試してみてください。


