目次
前編
後編
- はじめに
- Grafanaのデプロイ
- Grafanaによるデータの可視化
- まとめ
はじめに
この記事では前編・後編の2回に分けて、enebularで収集・蓄積したIoTのデータを、データ可視化ツールのGrafanaで可視化する方法を紹介します。
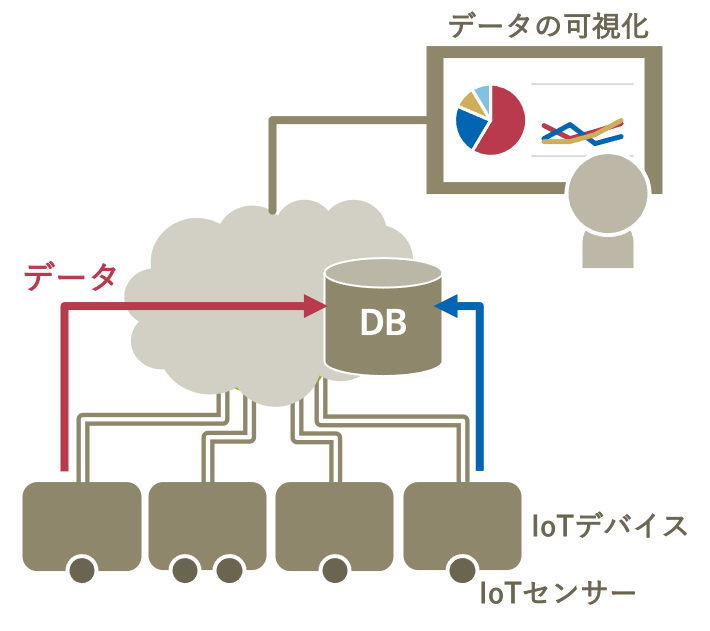
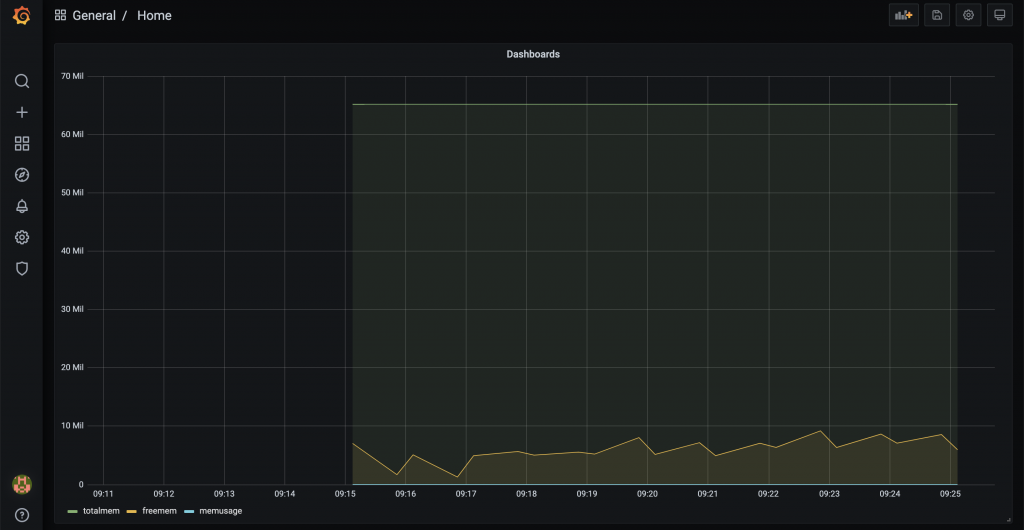
典型的なIoTシステムでは、図のようにセンサーから収集したデータをデータベースに蓄積して、可視化したり分析したりします。今回は、データベースへのデータ蓄積部分をenebularで、データの可視化の部分をGrafanaで実現します。最後には下の図のようなグラフを表示するのが目標です。
前編では、enebular(Node-RED)を利用してデータベースにデータを蓄積します。
後編では、データベースに蓄積されたデータを、Grafanaで可視化します。
前編は、enebularでPostgreSQLを利用するためのチュートリアルにもなっていますので、Node-REDでデータベースを操作することに興味のある方は、参考にしてみてください。また、この記事で紹介する方法は、すべて無料で試すことができます。安心して試してみてください。
Grafanaとは
Grafanaは、Grafana Labs社が開発しているオープンソースのデータ可視化ツール(*1)です。
さまざまなデータソースと接続して、簡単にデータを可視化することができるので、とても人気がある可視化ツールです。
しかも、Docker Hub上にコンテナイメージが公開されているということで、より簡単にデプロイして実行することができるようになっています。
システム構成
この記事で作るシステムの全体構成を説明します。
図の2つのHeroku Dynoの上で動作する2つのアプリを作ります。
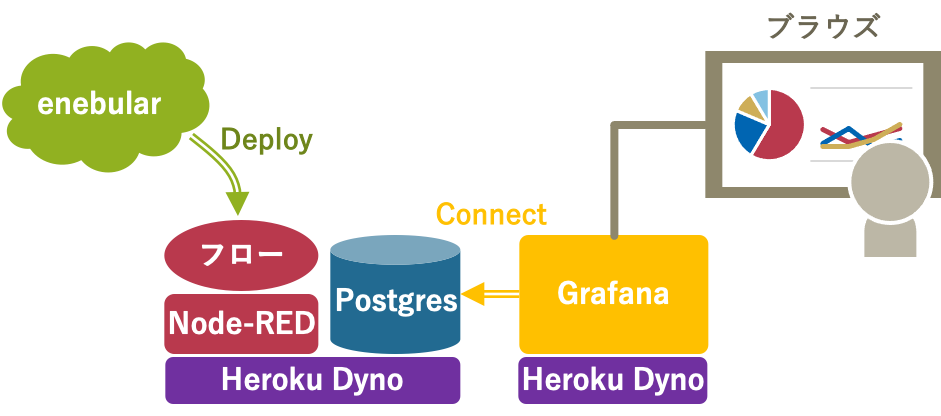
- enebularで開発したNode-REDのフローをHerokuのDynoの上で動作させます
- 1のHeroku Dynoで、Add-onの”Heroku Postgres”を動作させます。データはこのPostgreSQLに蓄積します
- Grafana(のコンテナ)をHeroku Dynoにデプロイして動作させます
記事の前編では1と2を作成します。記事の後編では3を作成します。
ここで使用するHerokuのDynoやAdd-onは、すべて無料で使用できるものです。
Heroku Postgresは、無料で使用した場合には10000レコードという制限があります。
実際のシステムで使用する場合は、レコード数制限に気をつけて使ってください。
サンプルフロー
まずは、可視化するためのデータを収集して蓄積するためのフローを作成します。
今回は、それっぽいデータを収集しやすいという理由で、サーバーのメモリ使用量を収集・蓄積します。
(蛇足ですが、HerokuのFree Dynoでは、Metricsの機能が使えないのでちょうど良いですね)
データベースは、PostgreSQLを使います。ご存知の方は少ないのですが、enebularではHerokuにフローをデプロイをする際に、”Heroku Postgres”のアドオンも有効にしています。せっかくなので、今回はこのPostgreSQLにデータを蓄積してみます(*2)。
フローを作成してデプロイする実際の手順は、以下のようになります(enebularのアカウントと、Herokuのアカウントは準備しておいてくださいね(*3))。
- enebularに新規のプロジェクトを作る
- サンプルのフローをDiscoverからインポートする
- 1度フローをHerokuにデプロイする
- フローを設定する
- データベースを設定する
- Herokuにフローをデプロイする
では、ステップバイステップで手順を説明していきます。
最後に今回使用するフローの内容を説明します。先に知りたい方は、ググッと下にスクロールしてみてください。
enebularに新規のプロジェクトを作る
プロジェクトは、以下の手順で作成できます。
マニュアルの”Project”にも図解入りで説明があるので参考にしてみてください。
- enebularにサインインする
- Dashboard画面から”Create Project”ボタンを押す
- プロジェクト名を入力してSubmitボタンを押す
サンプルのフローをDiscoverからインポートする
今回使用するサンプルのフローは、enebularのDiscoverに公開しています。
以下の手順で、自分のプロジェクトにインポートしてください。
(マニュアルの”Discover”も参考にしてくださいね)
成功すると下図のようなフローがインポートされます。
- Discover画面からフローを検索する
- 検索ボックスに”heroku-grafana-postgres-blog”と入力してください
- 見つかったフローをクリックする
- 表示された”Import”ボタンを押す
- ProjectとPrivilegeの入力を要求されるので、先ほど作成したプロジェクトを指定する(Privilegeはデフォルトのまま)
- Importボタンを押す
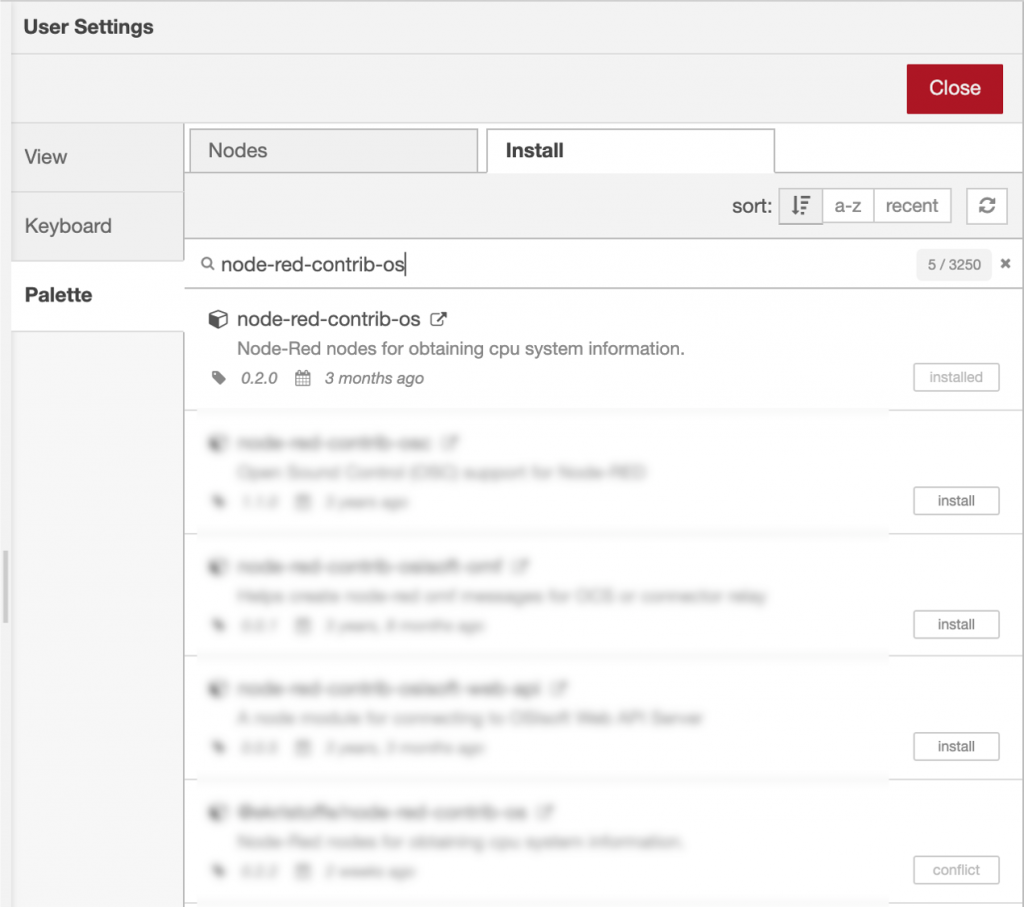
このサンプルフローは、追加で2つのノードを新規でインストールして使用します。
インポートされたフローをフローエディタで開いて、ノードのインストールを行います(手順の下に画面のスクリーンショットを載せていますので、参考にしてください)。
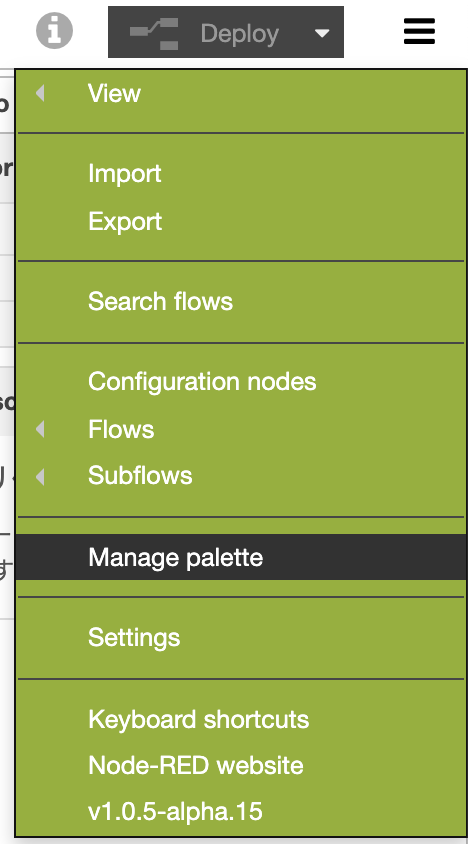
- エディタのメニューから”Manage palette”を選択する
- Paletteの”Install”タブで、以下の2つのノードをインストールする
- node-red-contrib-os
- node-red-contrib-re-postgres
フローエディタのメニュー画面
フローエディタのManage Palette画面
1度フローをHerokuにデプロイする
Discoverからインポートしたフローは、みなさんの環境に合わせて設定をしないと動作してくれません。
ここで、みなさんの環境というのは、HerokuやPostgreSQLのことなのですが、この段階ではまだPostgreSQLが動作していません。
まずは、1度、フローをHerokuにデプロイして環境を作成するのがこの手順です。
デプロイしてもフローは動作しないのですが、この手順の後であらためてフローを修正して、デプロイし直しますから心配しないでください。
ここでは、ごく簡単に手順を示します。Herokuへのフローのデプロイ手順は、少し難しいのでマニュアルの”Herokuへのデプロイ”を読んでみてください。
- enebularでフローを選択する
- “Deploy”ボタンを押す
- Select Connection for Deployment画面が表示されるので”Add Connection”ボタンを押す
- Create Connection画面で、Connection Typeを”Heroku”にして、Connection NameとHeroku API Tokenを入力する(Heroku API Tokenの取得方法は、マニュアルに記載されています。ちょっと面倒ですが、よく読んでくださいね!)
- 作成したConnectionを選択する
- 選択したConnectionの画面で”Deploy to Heroku”ボタンを押す(App Nameのリストが表示される場合がありますが、そちらは選択しないでください)
- 新しくタブが開いてHerokuの”Create New App”画面が表示されるので、App NameとPASSWORDとUSERNAMEを入力して、”Deploy App”ボタンを押す
以上の手順で、Herokuに新しいアプリが作成されて、フローがデプロイされます。
フローを設定する
Herokuにアプリがデプロイされて、アプリ内のPostgreSQLが有効になりました(Heroku Postgresアドオンが有効になった)。
このPostgreSQLの環境を参照しながら、フローを設定していきます(手順の下に画面のスクリーンショットを載せていますので、参考にしてください)。
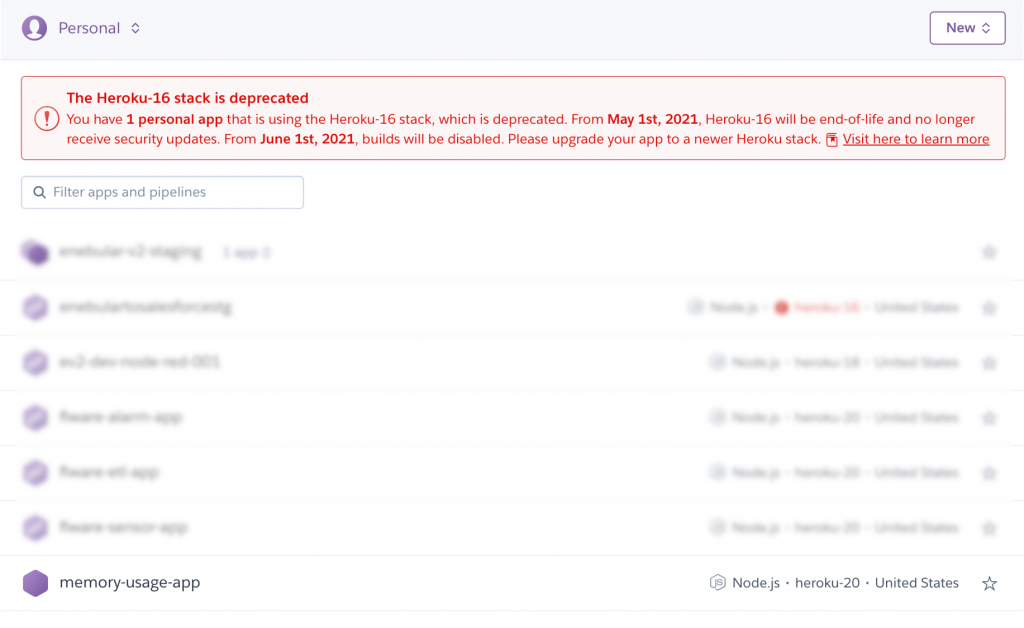
- Herokuのダッシュボードを開いて、デプロイしたアプリを選択する
- “Resource”タブを開いて、”Heroku Postgres”アドオンをクリックする
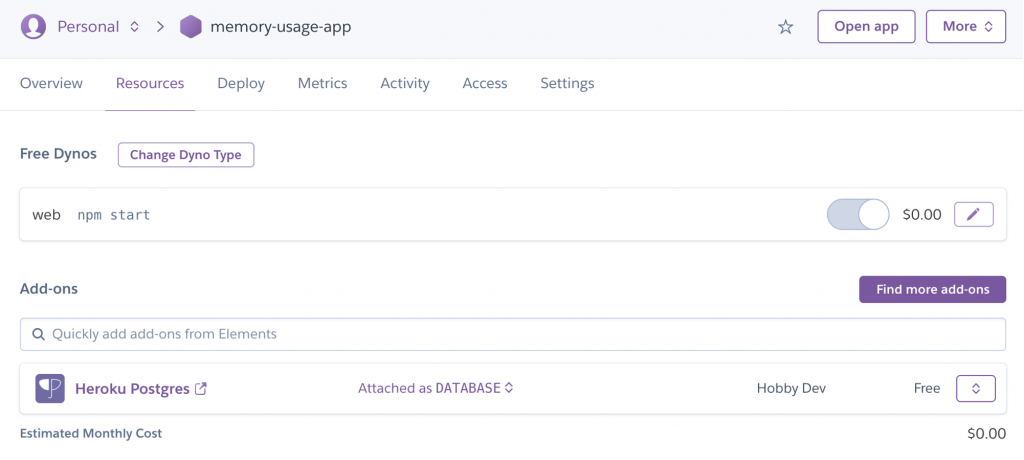
- 新しくタブが開いて、アドオンの画面が表示されるので、”Setting”タブを選択する
- “View Credential”ボタンを押して、Host、Database、User、Port、Password、URIをメモする
- enebularに戻って、Discoverからインポートしたフローを選択して、フローエディタを起動する
- Postgresノードを選択して設定画面を開く
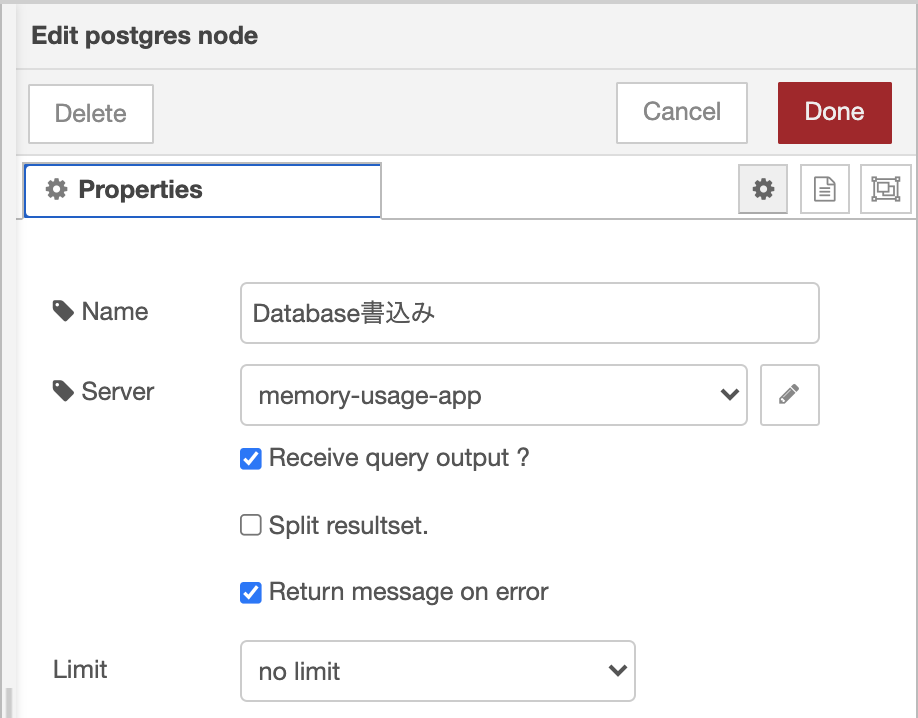
- Postgresノードの設定画面内のServerのボタンを押してコンフィグレーション画面を開く
- メモしたHost、Database、User、Port、Passwordを設定して、さらにUse SSLをチェックして保存する(”Update”ボタンを押す)
- “Done”ボタンを押して、設定画面を終了する
- 右上の”Deploy”ボタンを押してフローを保存する
Deployボタンを押して保存できたら、フローエディタは閉じて構いません。
Herokuダッシュボード
HerokuダッシュボードのResourceタブ
Heroku PostgresアドオンのSettingタブ
Postgresノードの設定画面
Postgresノードのコンフィグレーション画面
データベースを設定する
PostgreSQLを設定して、データを蓄積できるようにします。
メモリ情報を蓄積するデータベースは以下のような構造にします。テーブル名は、memory_usageとしましょう。
| カラム | タイプ | プライマリーキー |
|---|---|---|
| id | serial | * |
| ts | timestamp with time zone | |
| totalmem | integer | |
| freemem | integer | |
| memusage | real |
では、実際にテーブルを作成しましょう。
テーブルの作成には色々な方法がありますが、ここではpsqlを使った方法を説明します。公式サイトを参照しながらPostgreSQLをインストールしてください。psqlコマンドが使えるようになります。
- psqlをHeroku上のPostgreSQLに接続します
- データベースに接続されたpsqlの上で、CREATE TABLEを実行します
- 確認のためにpsqlで、
¥d memory_usageと打ってみましょう。テーブル定義が表示されればテーブル作成が成功しています
psql接続のためのコマンド
psql -d "URI"
(URIは”フローを設定する"でメモしたURIのこと)
CREATE TABLEのコマンド
CREATE TABLE memory_usage (
id serial,
ts timestamp with time zone,
totalmem integer,
freemem integer,
memusage real,
PRIMARY KEY(id)
);
¥dコマンドの結果
Column | Type | Collation | Nullable | Default
----------+--------------------------+-----------+----------+------------------------------------------
id | integer | | not null | nextval('memory_usage_id_seq'::regclass)
ts | timestamp with time zone | | |
totalmem | integer | | |
freemem | integer | | |
memusage | real | | |
Indexes:
"memory_usage_pkey" PRIMARY KEY, btree (id)
Herokuにフローをデプロイする
フローの設定ができたので、今度こそ動作するフローをHerokuにデプロイします。
- enebularでフローを選択する
- “Deploy”ボタンを押す
- Select Connection for Deployment画面が表示されるので、1度フローをHerokuにデプロイするで作成したコネクションを選択する
- 選択したConnectionの画面で、1度フローをHerokuにデプロイするで作成したアプリを選択して”Deploy”ボタンを押す(今度はDeploy Appではありません。注意してください)
動作確認をしたい場合は、Herokuのダッシュボードで、デプロイしたアプリを”Open app”してみてください。
Node-REDの画面が起動します。ユーザー名とパスワードの入力が要求されるので、1度フローをHerokuにデプロイするで入力したユーザー名とパスワードを入力してください。これで、Herokuにデプロイされたフローの動作を通常のNode-REDと同じ画面で確認できます。
サンプルフローの説明
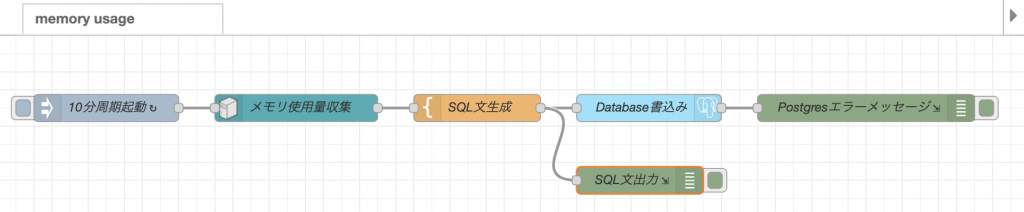
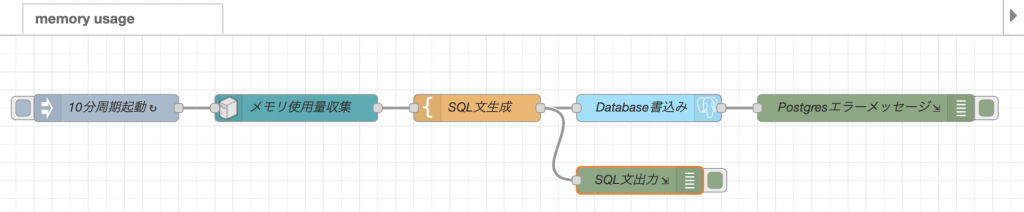
フローは、図のようになります。
このフローは、injectノードを利用して、10分周期で動作します。
フローが起動すると、Memoryノードでメモリの使用状況を収集します。
memoryノードの出力は、templateノードでSQL文の形に整形されます。
SQL文は、postgresノードに渡されて、データベースに書き込みが行われます。
injectノード

10分周期で、フローを起動します。周期を変更したい場合は、Repeatの設定を変更してください。
フローを起動するためだけに使用しているので、ノードの出力はなんでも構いません。
memoryノード

メモリの使用量を出力してくれます。
node-red-contrib-osの中のMemoryノードを使用しています。
Node.jsに詳しい方は、os.freemem()やos.totalmem()の出力が得られると思っていただければOKです(さらに、memusageということで、メモリの使用率も出力されます)。
templateノード

memoryノードの出力から、SQL文を作成しています。出力されるSQL文は、以下のような形です。
insert into memory_usage (ts, totalmem, freemem, memusage) VALUES(current_timestamp, 65158396, 7045360, 89.19)
templateノードの機能で、totalmem(=65158396), freemem(=7045360), memusage(=89.19)の値をMemoryノードの出力する値で設定しています。
postgresノード

Herokuで動作しているPostgreSQLに接続して、templateノードが出力するSQL文を実行します。
ここでは、node-red-contrib-re-postgresノードを使用しています。
PostgreSQL用のノードは複数ありますが、人気があってシンプルに利用できそうなノードを選んでみました。
まとめ
さて、「enebularとGrafanaでIoTのデータを可視化する方法(前編)」は、いかがだったでしょうか?
「enebularとGrafanaでIoTのデータを可視化する方法(後編)」では、いよいよGrafanaでのデータの可視化にチャレンジします!
*1 エンタープライズ版やクラウド版もあります。クラウド版を使えば、もっと簡単にこの記事と同じことができそうですが、有料アカウントが必要ということもあって残念ながら未検証です。興味のある方は、試してみてはいかがでしょうか。
*2 本来のIoTシステムでは、Raspberry PiなどでIoTデバイスを開発してセンサーデータを収集するところですが、この記事はGrafanaとの連携がポイントです。IoTデバイスの作成は別の記事に譲って、できるだけシンプルにデータ収集をしたいと思います。
*3 enebularのアカウントの作成(サインアップ)はサインアップページから行ってください。詳しい説明は、マニュアルの”Introduction”を参照してください。Herokuのアカウントは、Herokuのサインアップページから行ってください。
")

