先日のenebular meetupで、日本語の文章の分かち書きの話が出たので、日本語の形態素解析ができるノードを探してみました。MecabやChasenなどが有名だと思いますが、javascriptのライブラリで色々調べるとkuromoji.jsというのがあるようです。
Node-REDのノードとしても公開されていましたので、早速使ってみたいと思います。とても簡単だったので、Node-RED初めての方でもできるかと思います。
シンプルにつなげてみる
まずは、injectノードとDebugノードの間に接続します。

結果はこのようになります。素材は、青空文庫の「セロ弾きのゴーシュ」の最初の文章から引用しています。
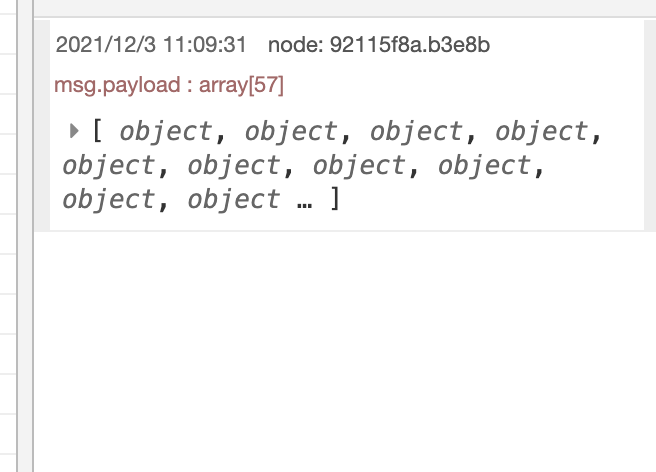
Debugタブ 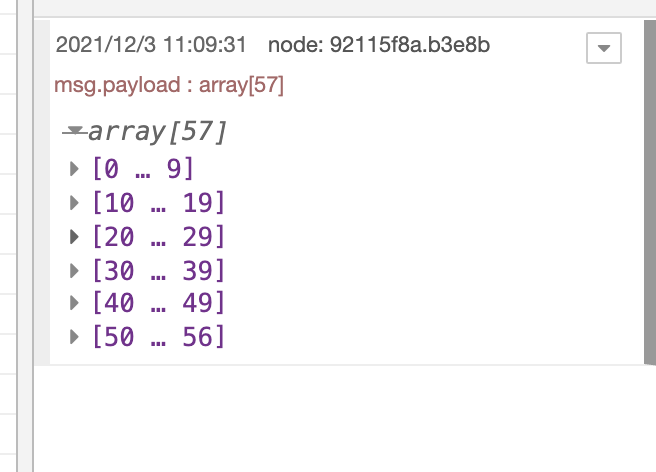
広げると配列 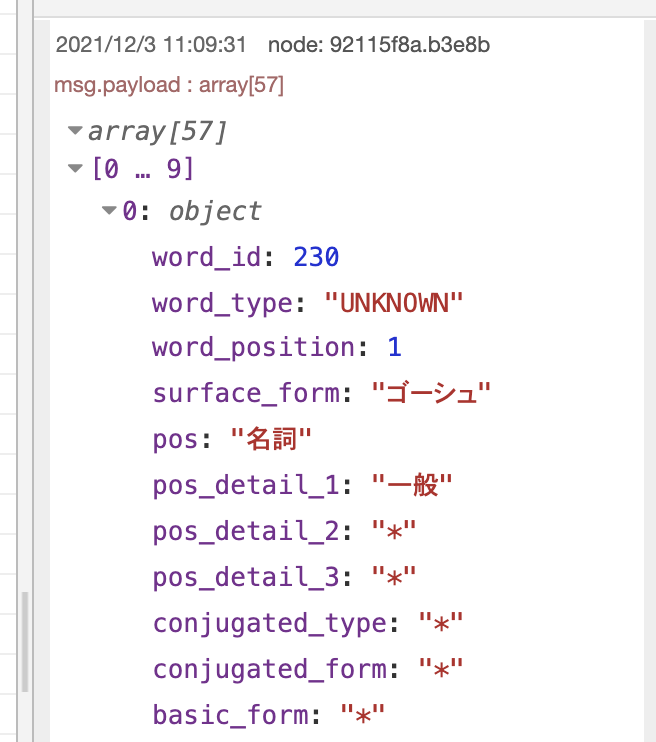
0番目(最初)のデータ「ゴーシュ」 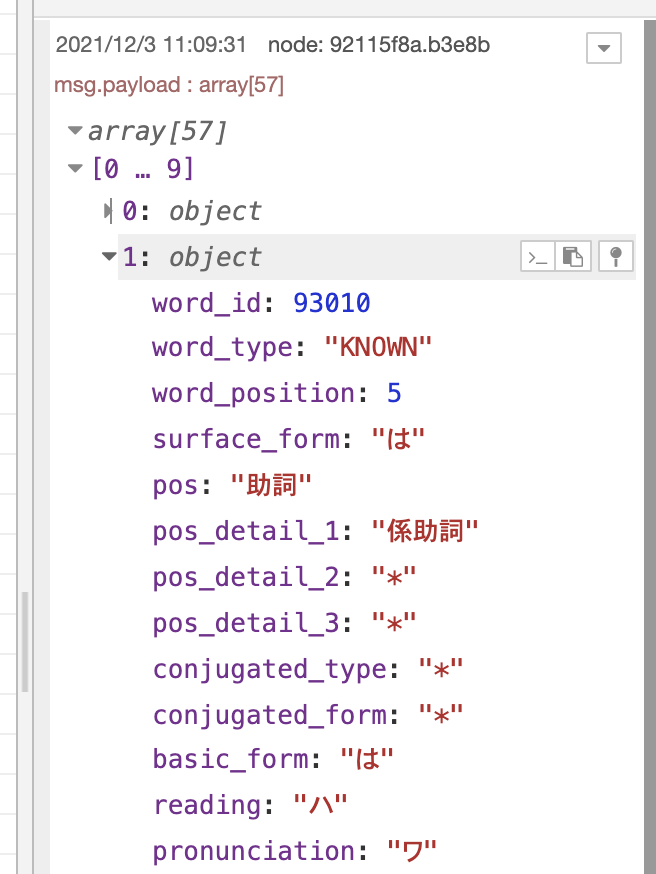
1番目のデータ「は」 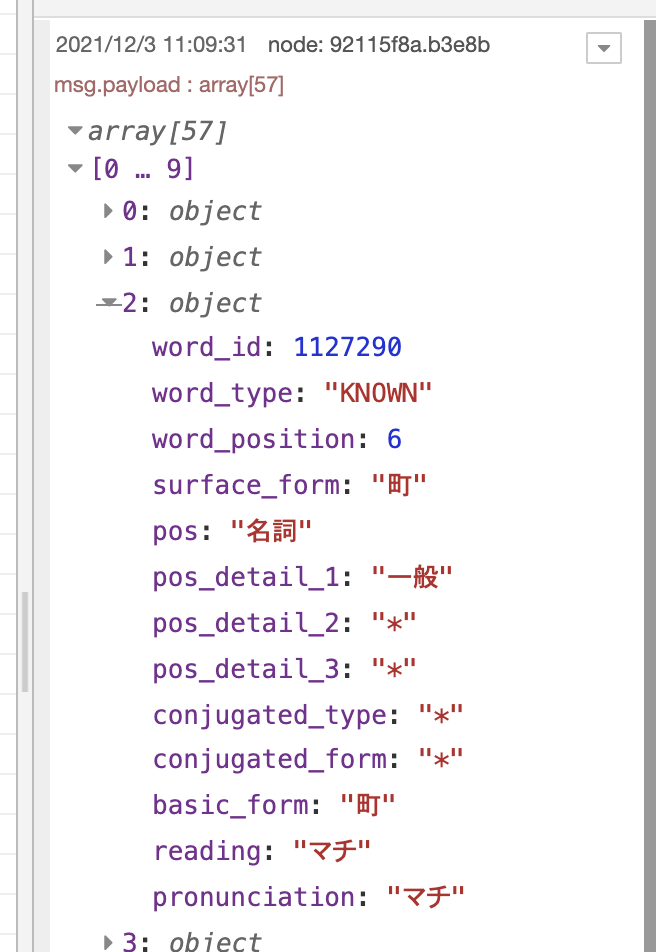
2番目のデータ「町」
分かち書きされた結果が配列になっています。
配列のままだと、扱いにくいので、分割してみましょう。
配列を分割する
分割するにはsplitノードを使います。

こんな感じで繋ぎます。

Injectノードをクリックしてみると、こんな結果になります。
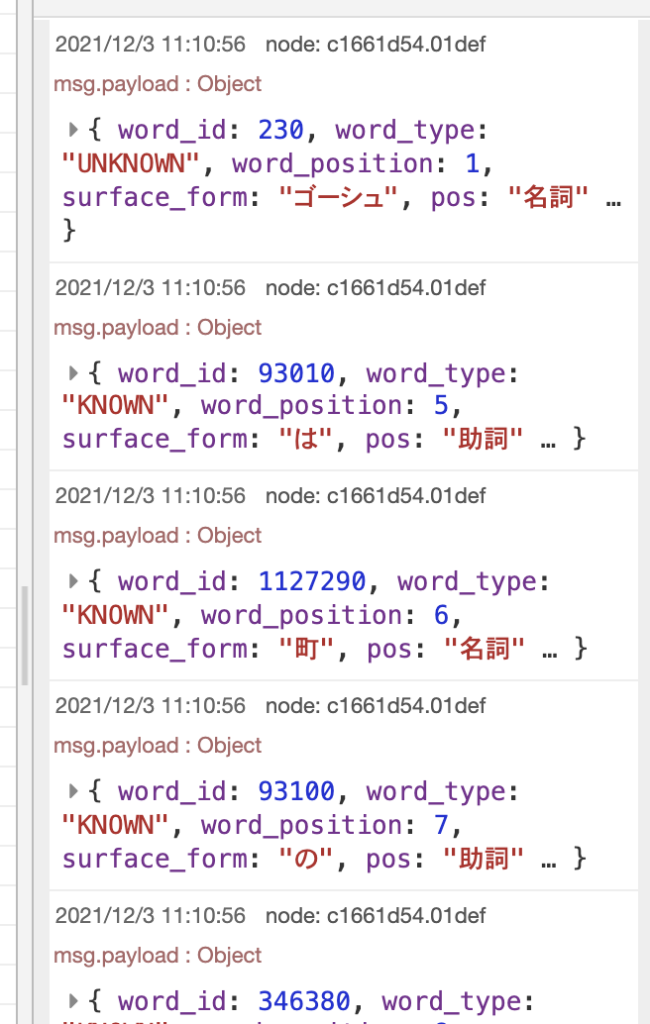
分かち書きされた単語のみならず、品詞の名前などの情報もあるようです。
とりあえず名詞だけ取り出してみたいと思います。
名詞を取り出す
名詞だけを取り出すには、分割されたメッセージのなかで、名詞を含んだデータだけフローを通過させればよいです。条件によって通過させるゲートの役割を担うのは、switchノードです。

こんな感じで、品詞が格納される場所は、msg.payload.posだということがわかるので、
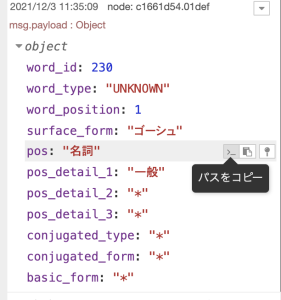
Switchノードのプロパティを、msg.payload.posの中身のデータが「名詞」という文字列に一致した場合にのみという条件にします。

作ったフローはこちらです。
実行してみるとDebugタブに表示されるのは名詞を含んだデータだけになりました。
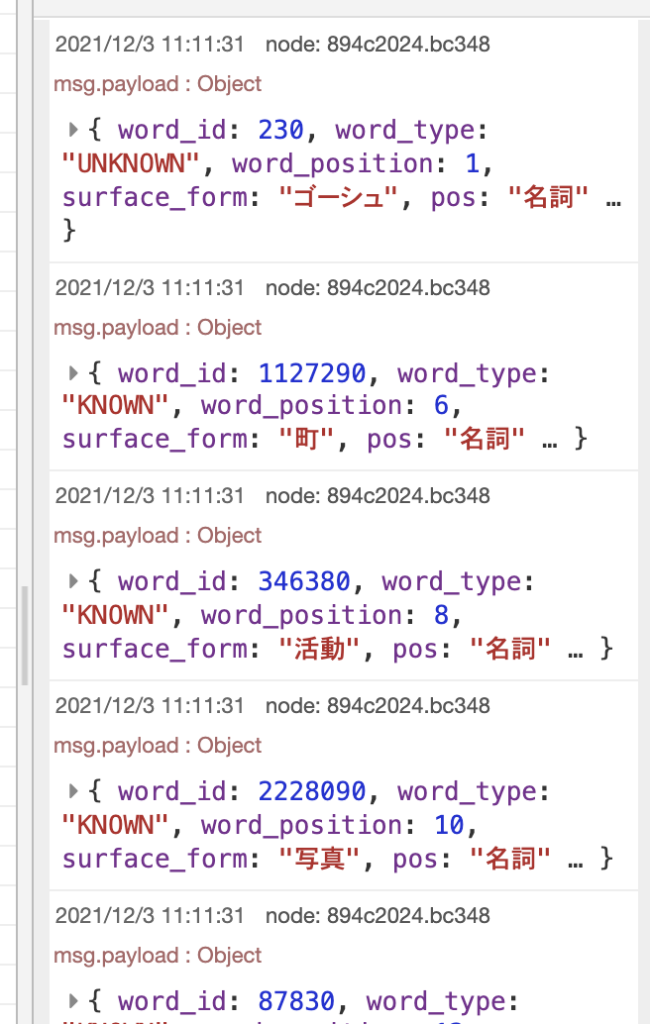
次に、分かち書きされた単語のみを取り出すことにします。
単語を取り出す
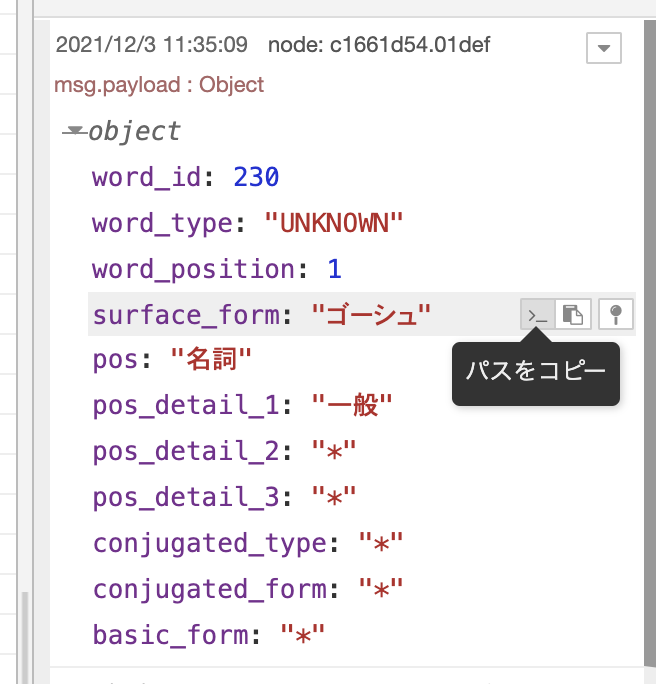
単語を取り出すには、changeノードを使います。

単語に相当する箇所のパスをコピーして、changeノードのルールに追加します。
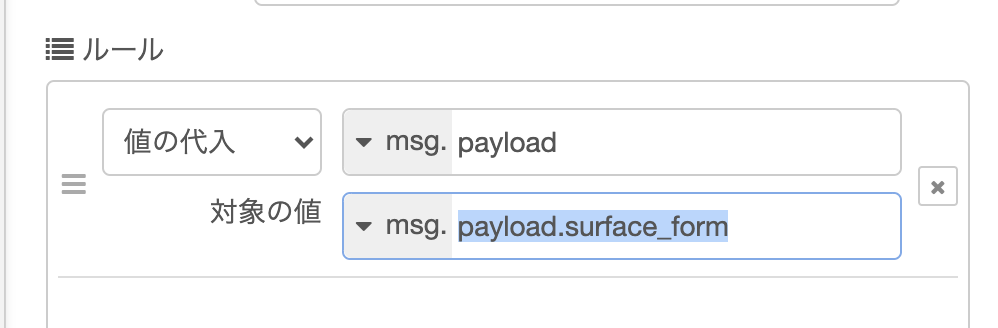
作ったフローはこちらです。
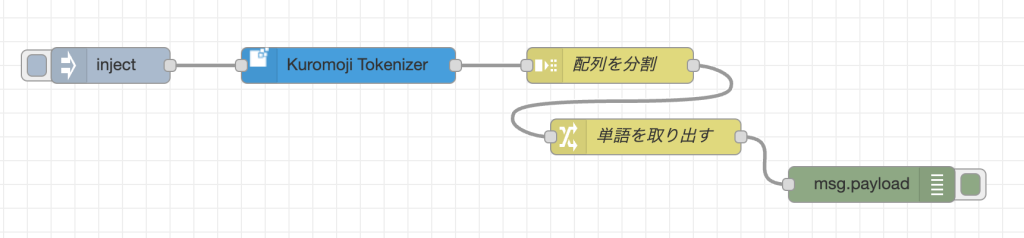
設定を保存して、Injectノードを実行します。
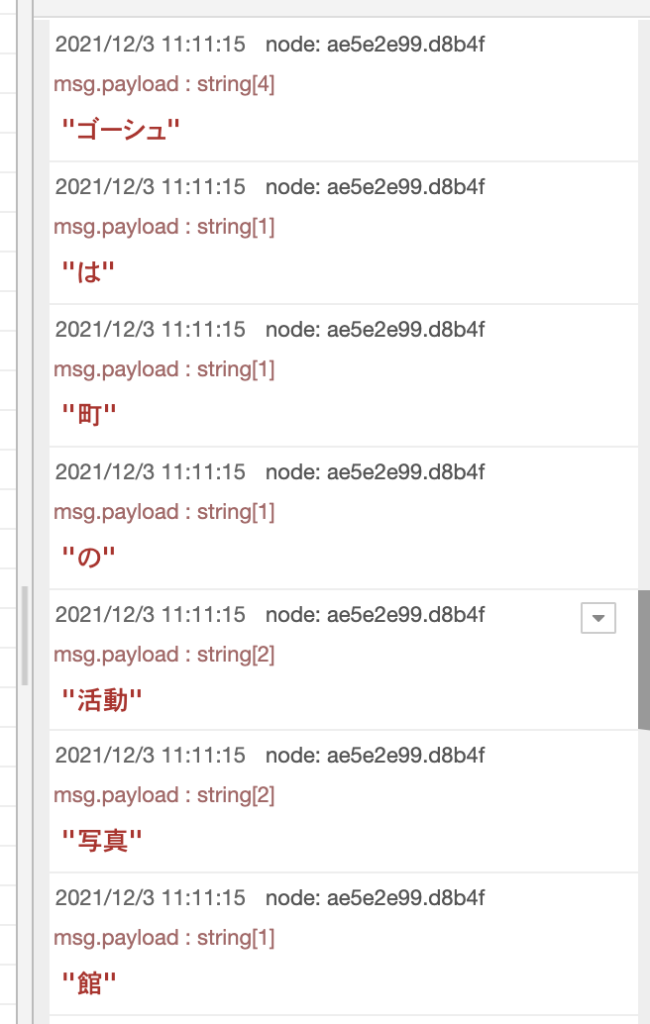
これで単語が取り出せました。
これらのフローを全部一緒にすれば、文章から名詞だけを取り出すフローが完成します。
完成したフローはこちらです。
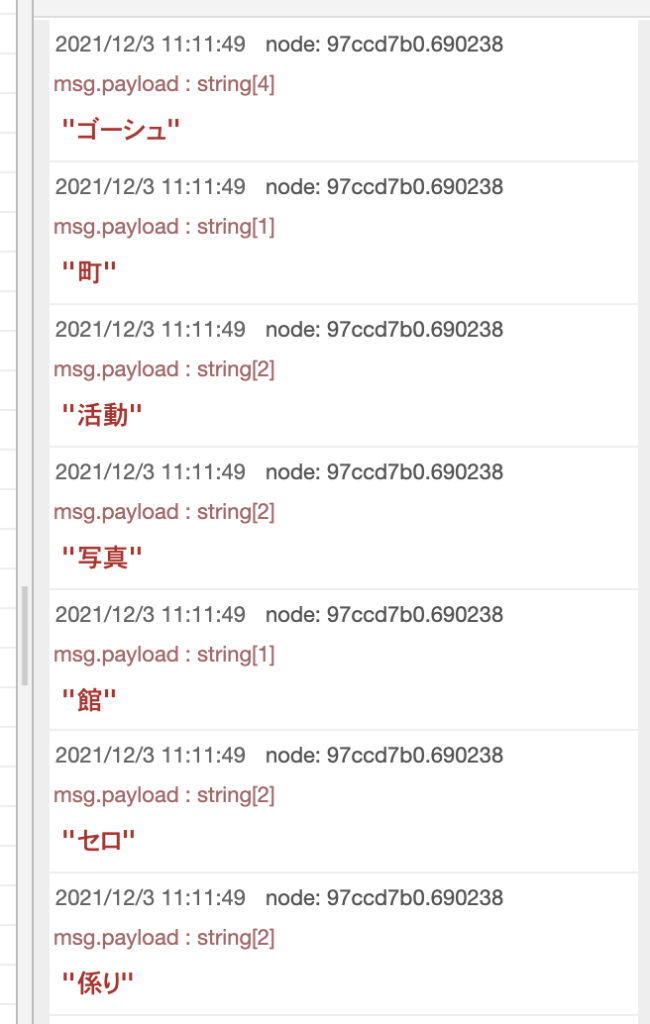
実行結果はこちらです。
まとめ
Node-REDで日本語の文章の分かち書きにより、名詞だけを取り出すことに成功しました。
Node-REDは、徐々に処理を追加して、自分の目的にあったデータの処理ができますので、プログラミング初心者の方でも簡単に扱うことができると思います。
今回作ったフローはDiscoverに公開していますので、興味のあるかたはぜひインポートしてみてください。
https://enebular.com/discover/flow/e0749f75-d361-4c11-a8ac-68f2cbe239ba


